Abstract
Collaborative 3D object detection exploits information exchange among multiple agents to enhance accuracy of object detection in presence of sensor impairments such as occlusion. However, in practice, pose estimation errors due to imperfect localization would cause spatial message misalignment and significantly reduce the performance of collaboration. To alleviate adverse impacts of pose errors, we propose CoAlign, a novel hybrid collaboration framework that is robust to unknown pose errors. The proposed solution relies on a novel agent-object pose graph modeling to enhance pose consistency among collaborating agents. Furthermore, we adopt a multi-scale data fusion strategy to aggregate intermediate features at multiple spatial resolutions. Comparing with previous works, which require ground-truth pose for training supervision, our proposed CoAlign is more practical since it doesn’t require any ground-truth pose supervision in the training and makes no specific assumptions on pose errors. Extensive evaluation of the proposed method is carried out on multiple datasets, certifying that CoAlign significantly reduce relative localization error and achieving the state of art detection performance when pose errors exist. Code are made available for the use of the research community at https://github.com/yifanlu0227/CoAlign.
Result
On the relational reasoning
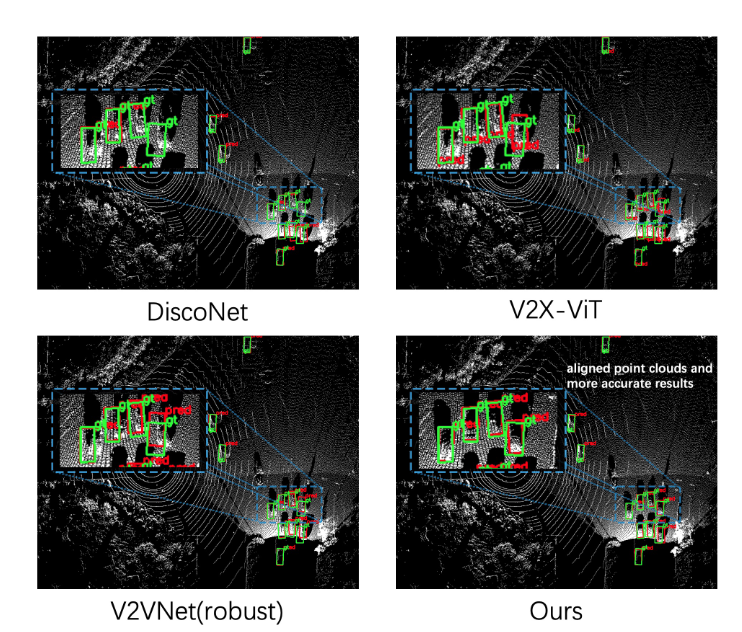
Visualization of detected boxes in DAIR-V2X dataset. Green boxes are ground-truth while red ones are detection. CoAlign achieves much more precise detection.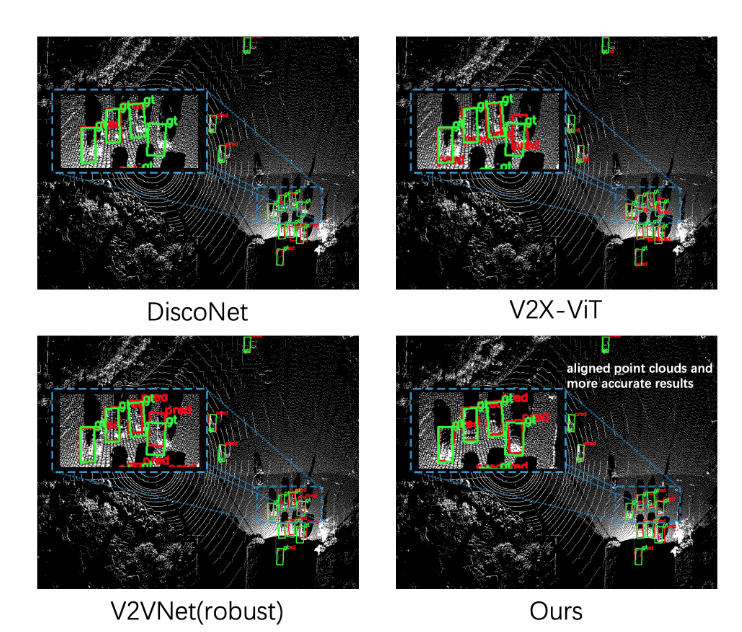
Detection performance on OPV2V, V2X-Sim 2.0 and DAIR-V2X datasets with pose noises following Gaussian distribution in the testing phase. All models are trained on pose noises following Gaussian distribution with σt = 0.2m, σr = 0.2. Experiments show that CoAlign holds the best resistance to localization error under various noise levels.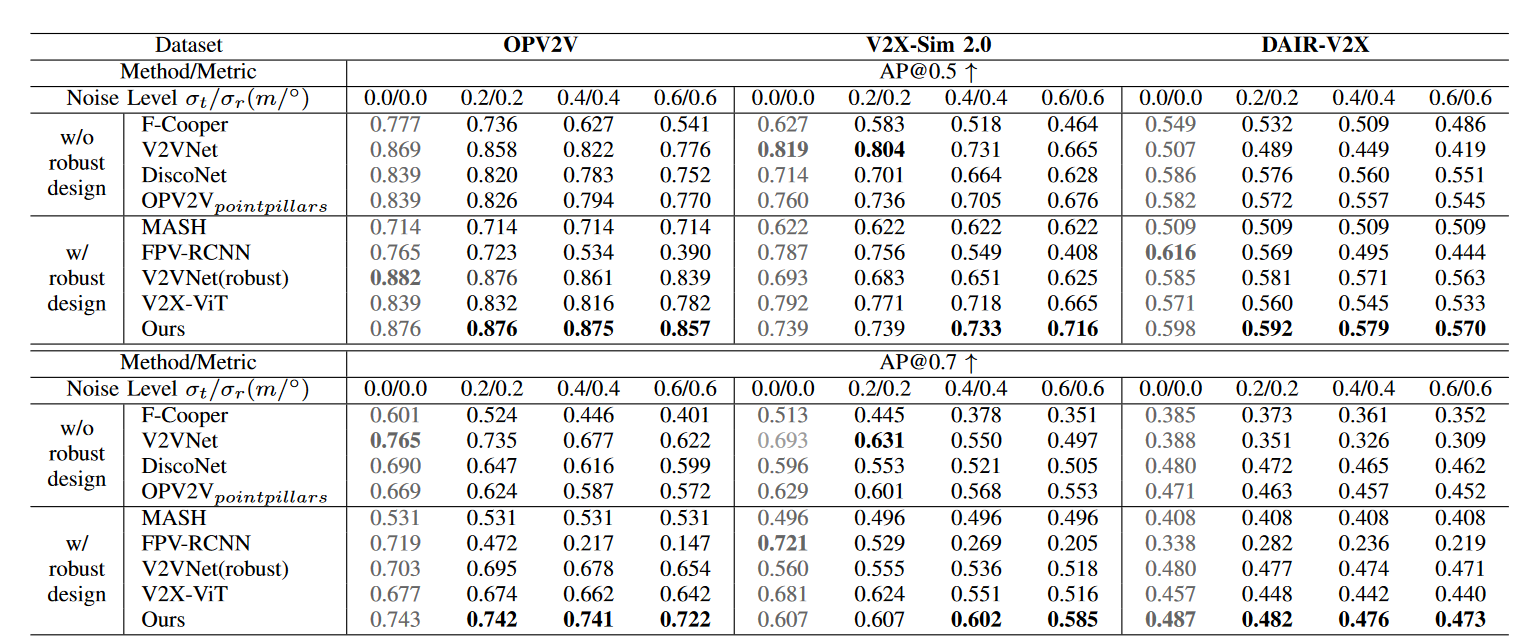
Citation
@article{lu2022robust,
title={Robust Collaborative 3D Object Detection in Presence of Pose Errors},
author={Lu, Yifan and Li, Quanhao and Liu, Baoan and Dianati, Mehrdad and Feng, Chen and Chen, Siheng and Wang, Yanfeng},
journal={arXiv preprint arXiv:2211.07214},
year={2022}
}
Acknowledgement
This research is partially supported by the National Key R&D Program of China under Grant 2021ZD0112801, National Natural Science Foundation of China under Grant 62171276, the Science and Technology Commission of Shanghai Municipal under Grant 21511100900 and CCF-DiDi GAIA Research Collaboration Plan 202112.